9.3 Ejemplos
En esta sección se van a explorar algunos de los gráficos estadísticos más básicos.
9.3.1 Diagramas de cajas (y de violín)
Los diagramas de caja (boxplots) describen de manera cruda la distribución de una variable continua en función de una discreta. En el ejemplo que aparece a continuación, se explora el conjunto de datos iris que contiene 50 observaciones de características métricas de cada una de las tres subespecies de iris, una flor. Es un conjunto de datos de larga tradición en estadística y se recopiló para ilustrar algoritmos de clasificación, es decir, cómo crear criterios para distinguir los tres tipos de iris.
library(reshape2)
tmp <- melt(iris)
ggplot(tmp, aes(x = Species, y = value)) + geom_boxplot() + facet_wrap(~ variable)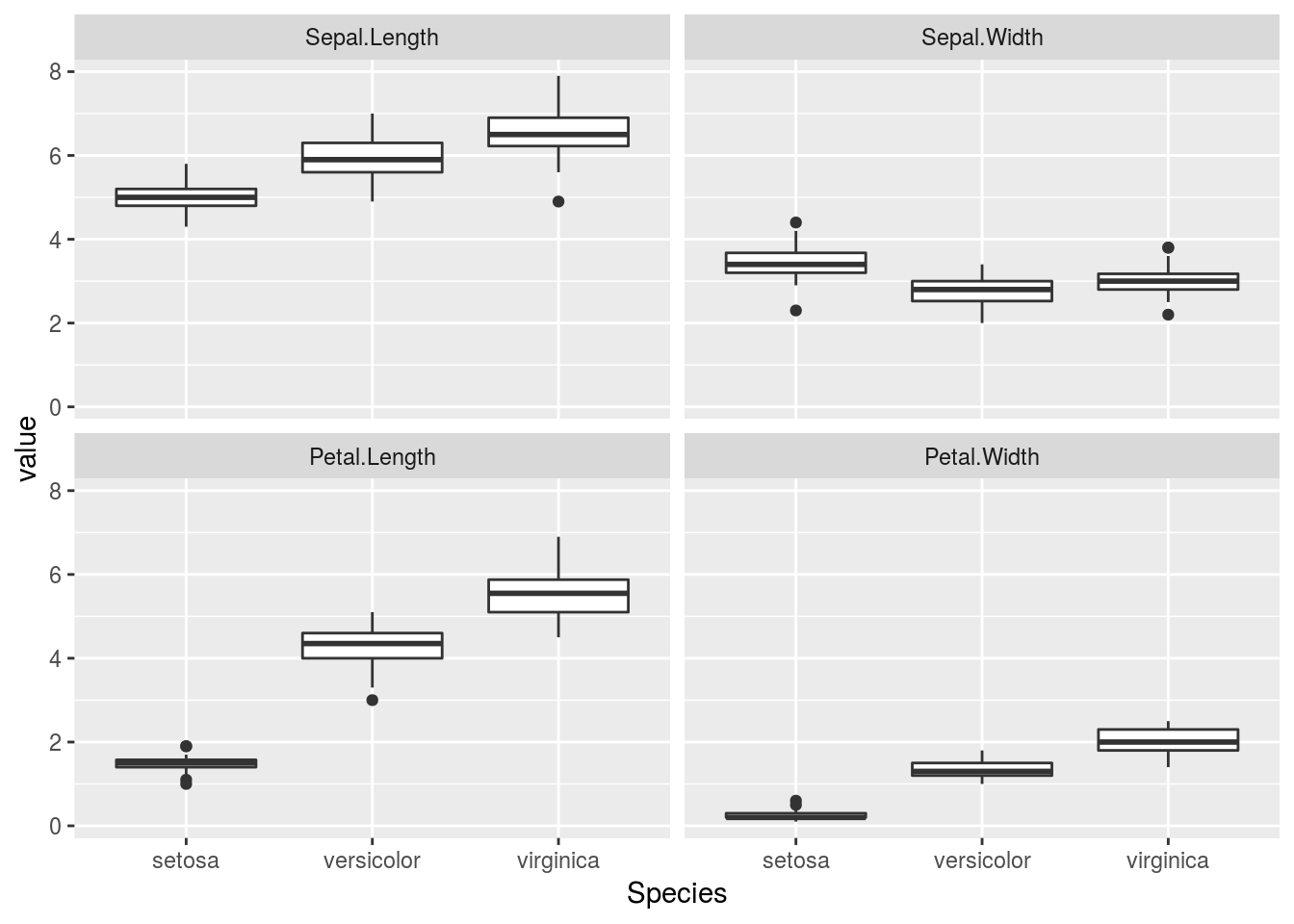
El gráfico utiliza las facetas para crear cuatro paneles, uno por variable. Así resume rápidamente la información contenida en el conjunto de datos y revela eficazmente los patrones que encierra: por ejemplo, cómo la especie setosa tiene el pétalo sensiblemente más estrecho y corto que las otras dos. Este tipo de gráficos son fundamentales como herramienta exploratoria previa a la aplicación de técnicas de análisis estadístico (discriminante, en este caso).
Los gráficos de cajas son muy básicos: apenas muestran cinco puntos característicos de una distribución: la mediana, los extremos y los cuartiles. Son herencia de una época en que apenas había recursos, principalmente informáticos, para realizar representaciones más sofisticadas. Una versión moderna de los gráficos de cajas es la de gráficos de violín. Como los de cajas, resumen la distribución de las variables. Pero en lugar de una representación sucinta, tratan de dibujar la distribución real de los datos: son verdaderos gráficos de densidad, solo que dispuestos de otra manera para facilitar la comparación.
ggplot(tmp, aes(x = Species, y = value)) +
geom_violin(fill = "lightblue") +
facet_wrap(~ variable)
9.3.2 Comparación de dos densidades
El análisis de datos exige en ocasiones comparar dos distribuciones continuas. Se pueden usar gráficos de cajas o de violín, como arriba, pero también se puede dibujar la distribuición completa como en el siguiente gráfico:
# datos (simulados)
a <- rbeta(1000, 2, 2)
b <- rbeta(2000, 2, 5)
# construcción de un dataframe a partir de ellos
tmp <- rbind(data.frame(origen = "a", dato = a),
data.frame(origen = "b", dato = b))
ggplot(tmp, aes(x = dato)) + geom_density() + facet_grid(origen ~ .)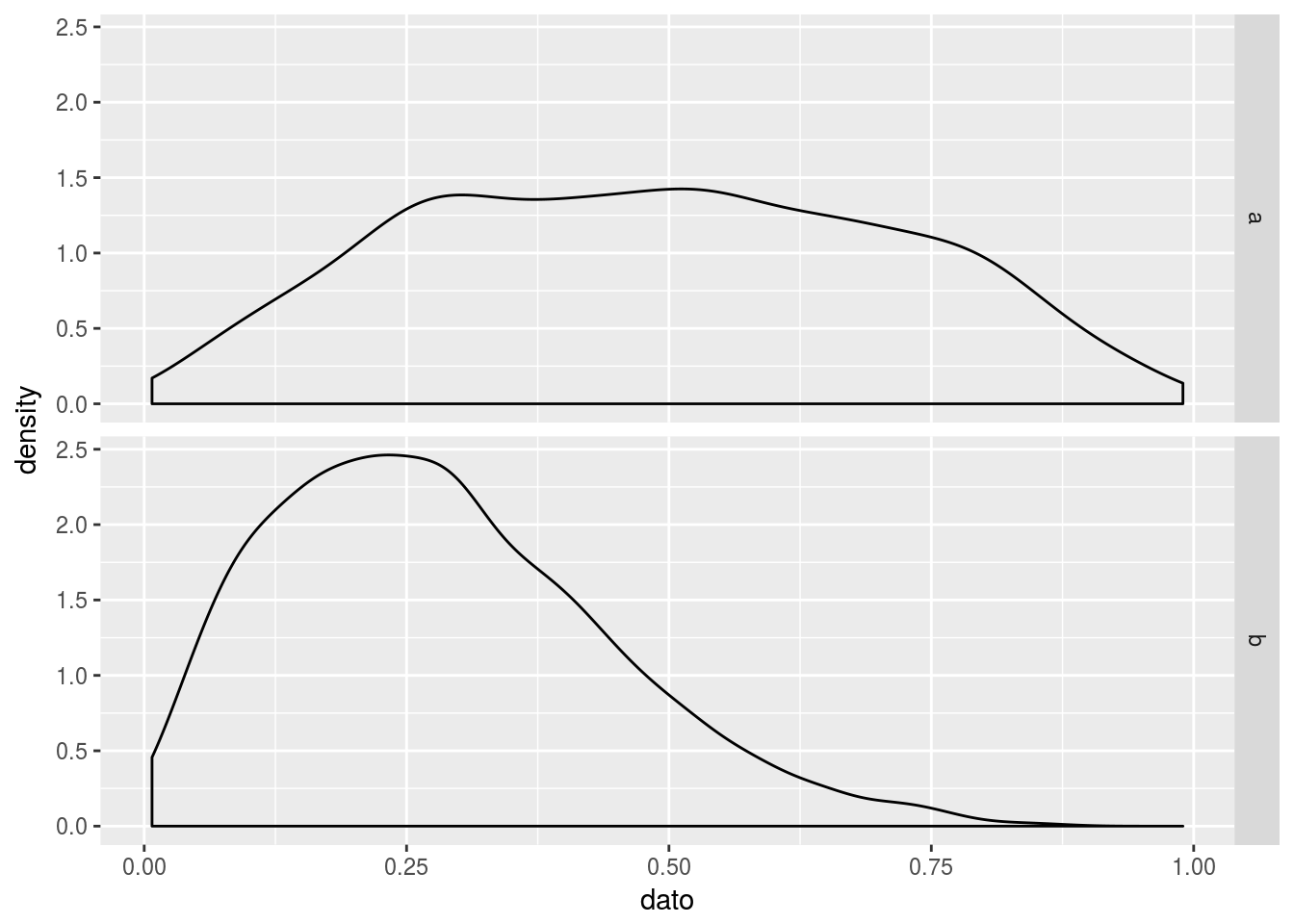
Alternativamente, se pueden solapar ambas distribuciones. El uso del parámetro alpha, que controla la transparencia, es fundamental en este caso:
ggplot(tmp, aes(x = dato, fill = origen)) + geom_density(alpha = 0.3)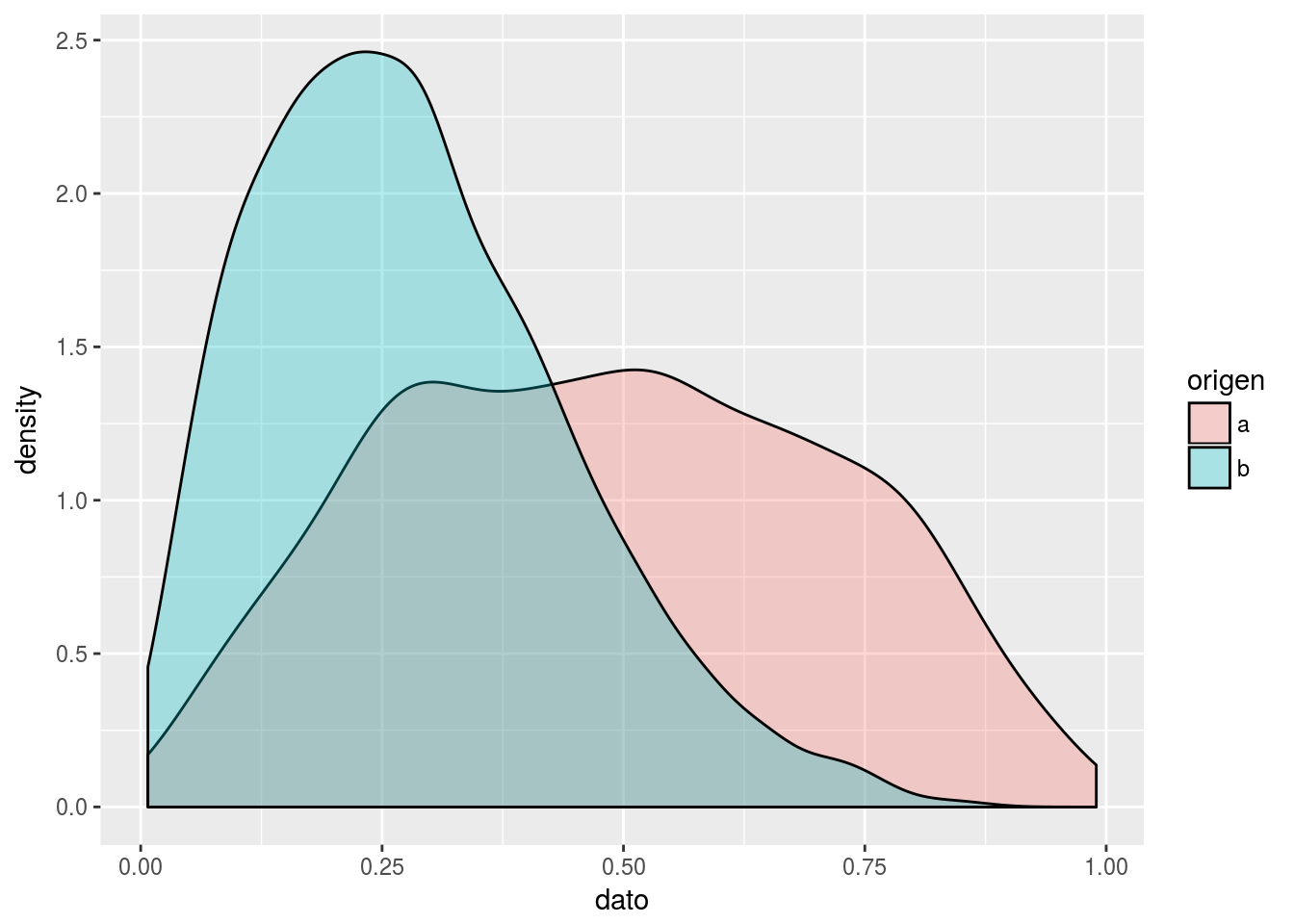
9.3.3 Series temporales
ggplot2 entiende ciertos tipos de datos particulares, como por ejemplo, series temporales. En el siguiente ejemplo se descargan las cotizaciones bursátiles de dos banco españoles directamente de Yahoo! Finance y se representan gráficamente:
library(tseries)
library(zoo)
library(reshape2)
# función para descargar las cotizaciones
cotizaciones <- function(valor){
res <- get.hist.quote(valor, provider = "yahoo",
quote = "AdjClose", quiet = TRUE)
colnames(res) <- valor
res
}
# combinación de ambas series temporales
res <- merge(cotizaciones("SAN.MC"),
cotizaciones("BBVA.MC"))
# construcción de un dataframe con un índice de tipo fecha
res <- data.frame(fecha = index(res), as.data.frame(res))
res <- melt(res, id.var = "fecha")
ggplot(res, aes(x = fecha, y = value)) + geom_line() + facet_grid(variable ~ .)
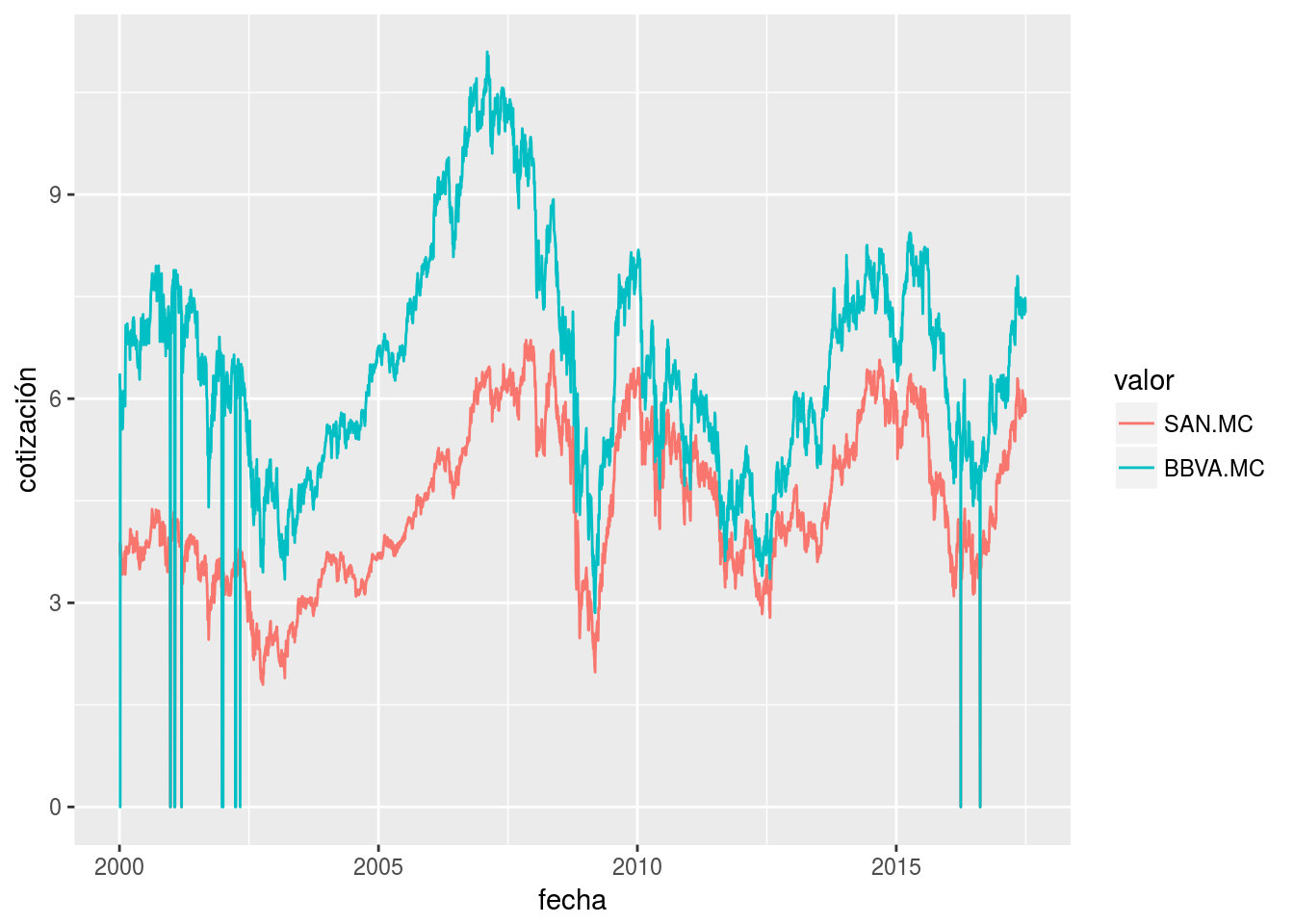
Una versión alternativa del gráfico es la que superpone las series usando colores para distinguirlas:
ggplot(res, aes(x = fecha, y = value, colour = variable)) + geom_line() +
labs(colour = "valor", y = "cotización")