2.6 Gráficos básicos
Esta sección es una introducción a los gráficos básicos en R. Los gráficos básicos (aunque luego veremos cómo construir otros más avanzados y vistosos) sirven esencialmente para examinar de manera visual y rápida conjuntos de datos.
Vamos a examinar los más habituales. Existen, sin embargo, muchos tipos más y hay libros enteros dedicados a ellos. Aunque nos restringiremos a los más comunes de ellos, en internet se pueden encontrar ejemplos de otros distintos además de información sobre cómo modificar sus parámetros por defecto: ejes, orientación de etiquetas, etc. Es un campo amplio y lleno de detalles pero que es más bien material de consulta puntual en un momento de necesidad que de exposición exhaustiva en un texto introductorio.
2.6.1 Gráficos de dispersión
Los gráficos de dispersión muestran la relación entre dos variables numéricas. En el ejemplo siguiente serán la velocidad y la distancia de frenado de un conjunto de coches recogidas en el conjunto de datos cars:
plot(cars$speed, cars$dist)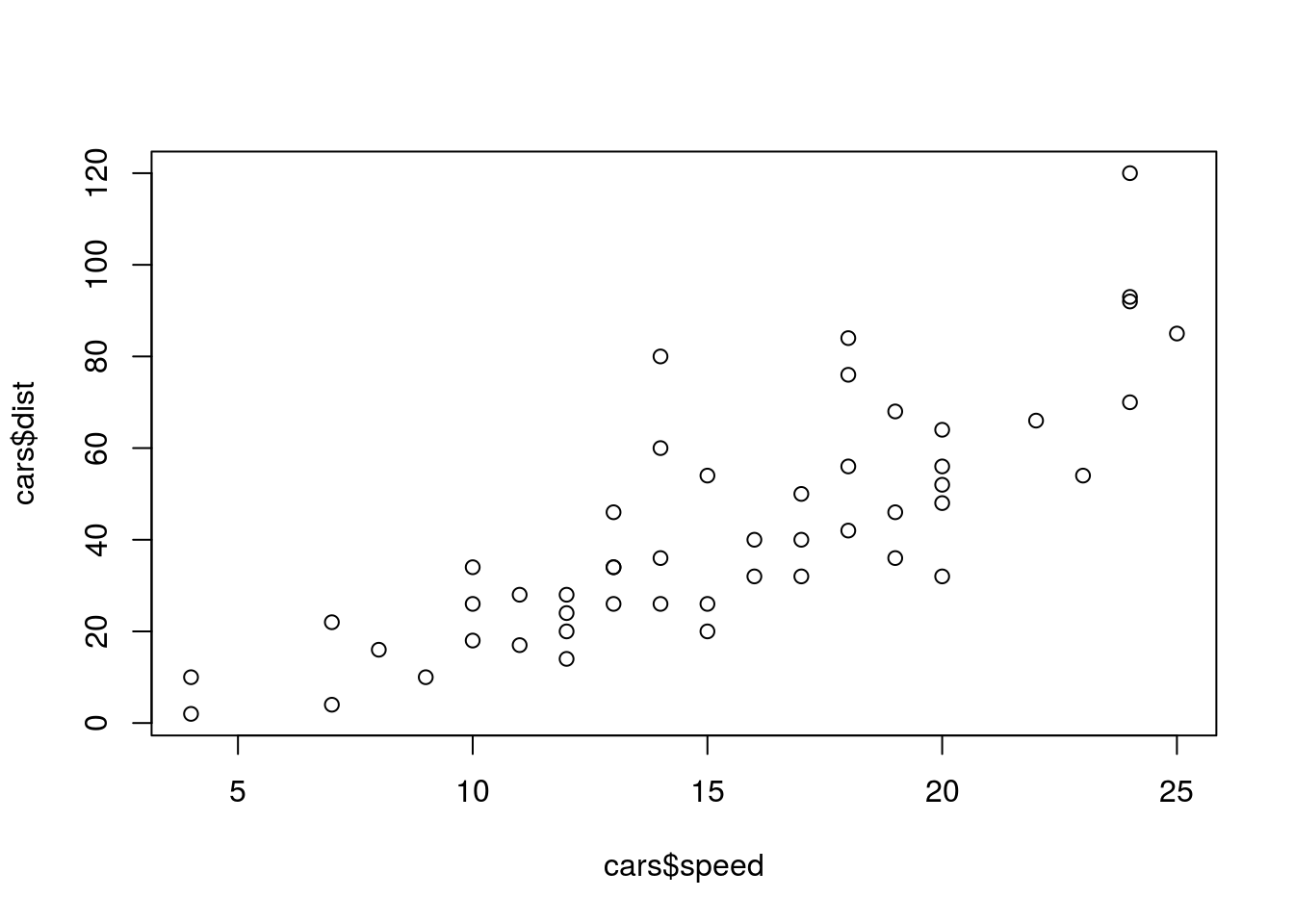
El gráfico muestra cómo aumenta dist en función de speed.
Representa gráficamente la anchura del sépalo contra su longitud (en iris).
Los gráficos admiten elementos adicionales que van añadiéndose progresivamente al lienzo:
plot(cars$dist, main = "Distancias de...",
ylab = "distancia en pies")
lines(cars$dist)
grid()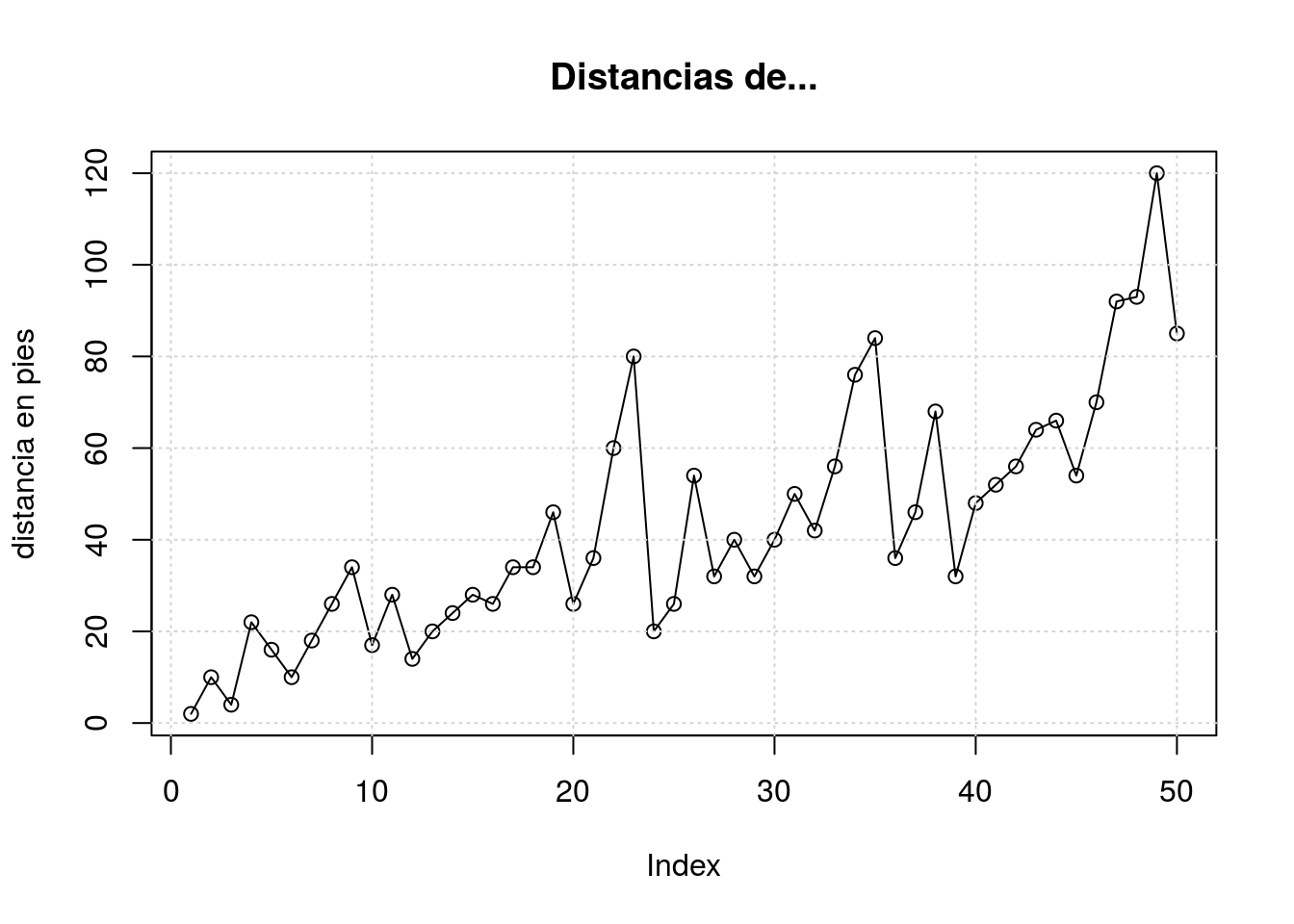
Consulta la ayuda de la función abline y úsala para añadir líneas a alguno de los gráficos anteriores.
Consulta ?par, una página de ayuda en R que muestra gran cantidad de parámetros modificables en un gráfico. Investiga y usa col, lty y lwd. Nota: casi nadie conoce estos parámetros y, menos, de memoria; pero está bien saber que existen por si un día procede utilizarlos.
2.6.2 Gráficos de barras
Los gráficos de barras muestran los valores de un vector, típicamente construido como el promedio de una serie de variables numéricas o el conteo de unas categóricas.
barplot(VADeaths[, 2], xlab = "tramos de edad", ylab = "tasa de mortalidad",
main = "Tasa de mortalidad en Virginia\nmujer/rural")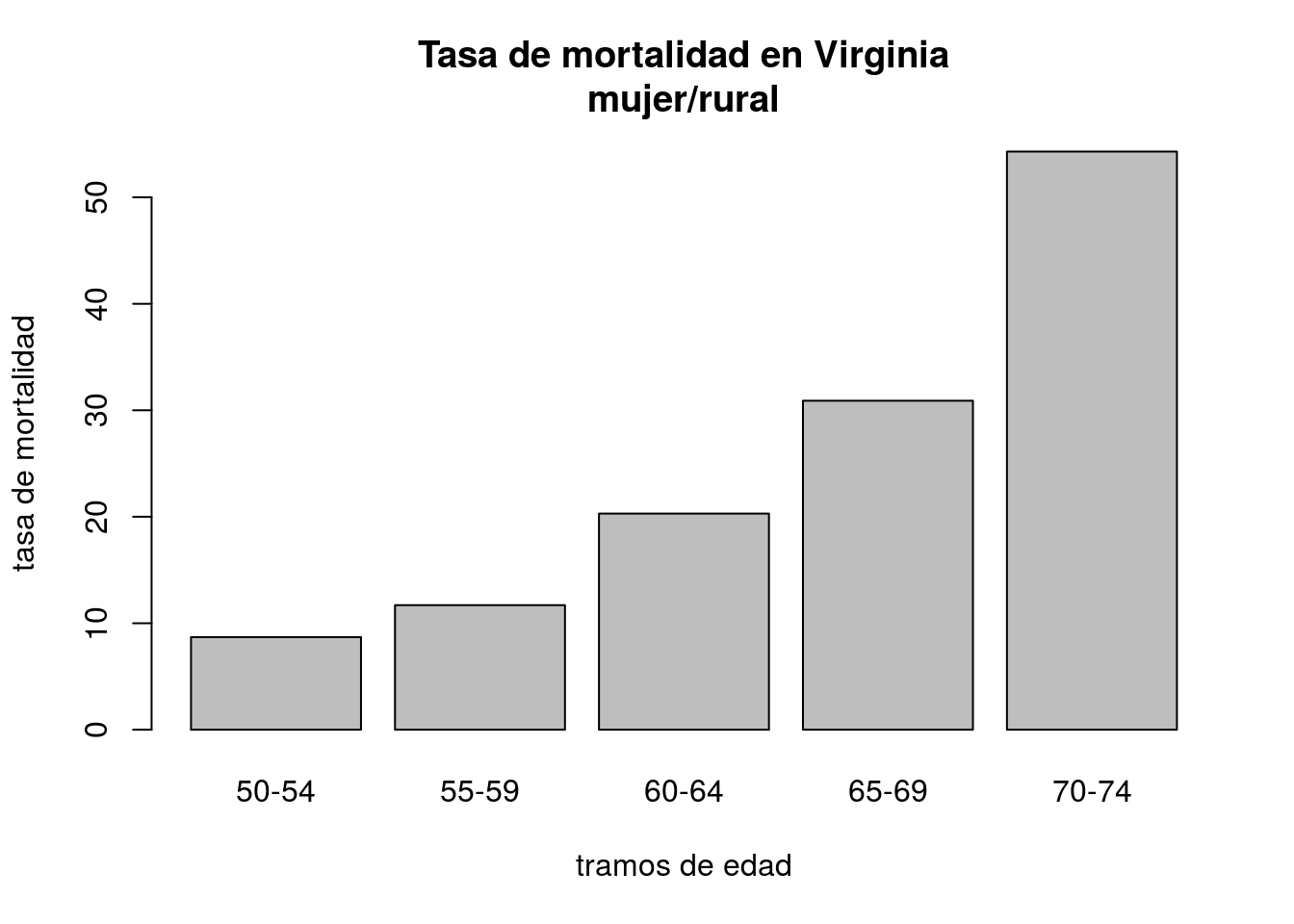
Mejora el gráfico anterior con el parámetro col (de color).
Los gráficos de puntos son alternativas recomendadas a las tradicionales barras:
dotchart(t(VADeaths), main = "Death Rates in Virginia - 1940", cex = 0.8)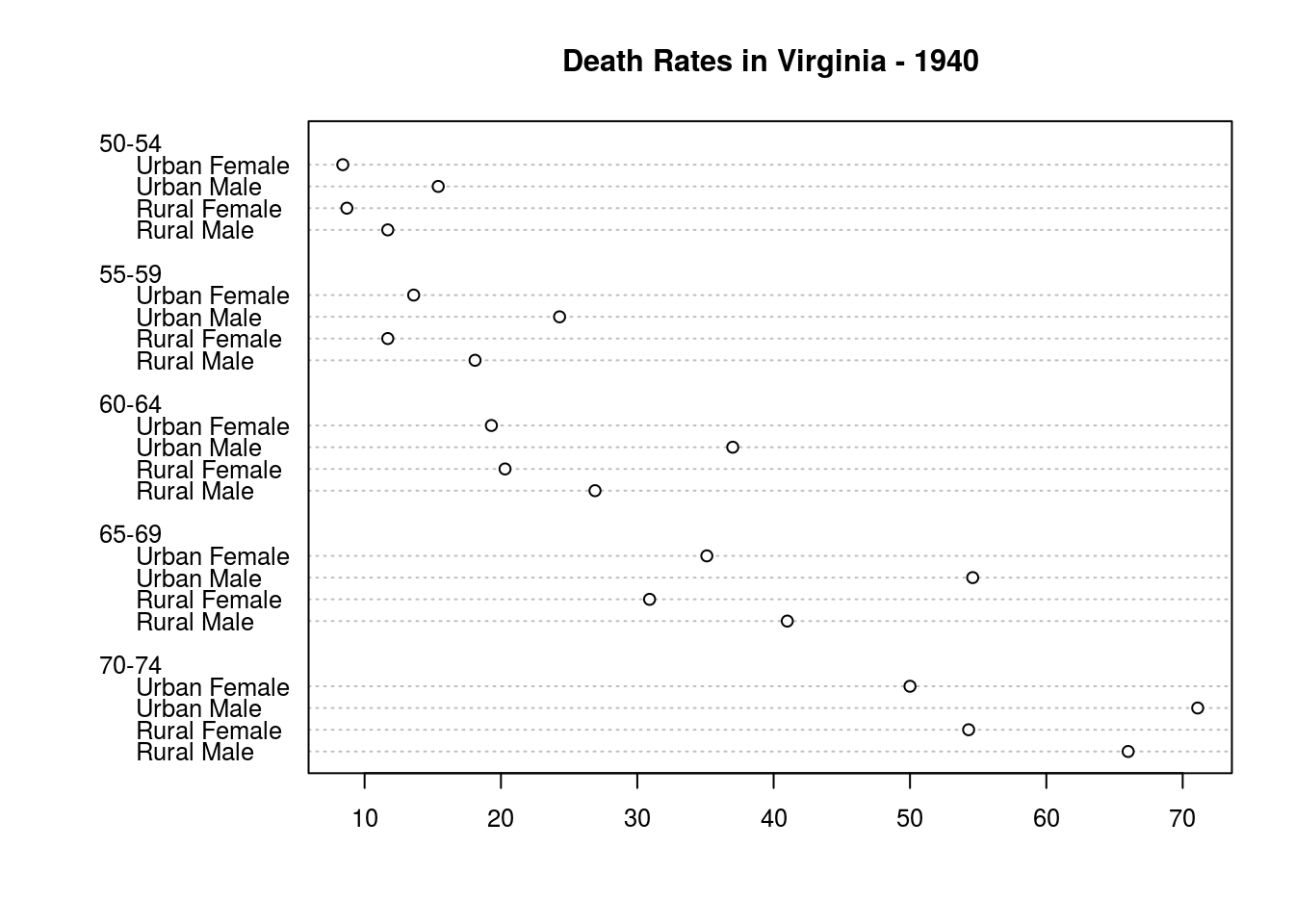
Los gráficos de barras exigen como parámetros o bien un vector o bien una matriz. En el primer ejemplo hemos usado como vector una columna de una matriz; en el segundo, una matriz completa (y la función de trasposición t).
La diferencia más importante entre las tablas y las matrices es que las últimas contienen datos de un mismo tipo (casi siempre, números), mientras que las tablas pueden mezclar columnas numéricas y no numéricas. En R se pueden realizar operaciones típicas de álgebra lineal (multiplicación matricial, matrices inversas, valores y vectores propios, etc.) operando, obviamente, sobre matrices.
2.6.3 Histogramas
Los histrogramas representan la distribución de un vector numérico. Un histograma es la manera más rápida de entender la forma de los datos (p.e., las edades de un conjunto de personas).
hist(iris$Sepal.Width)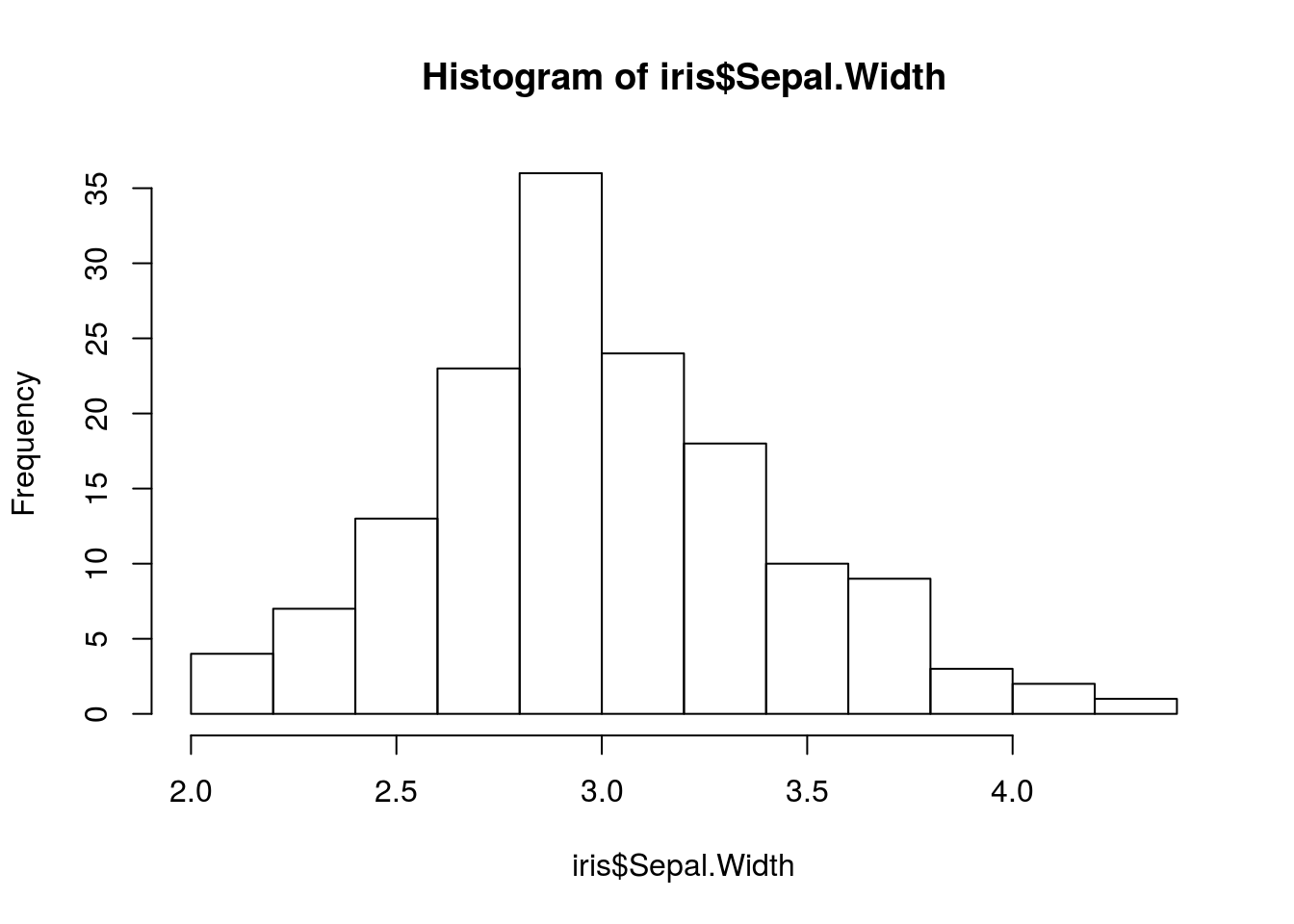
Estudia la distribución de las temperaturas en Nueva York (usa airquality).
Usa col para mejorar el aspecto del gráfico. Añádele un título y una etiqueta en el eje horizontal.
Usa abline para dibujar una línea vertical roja en la media de la distribución. Puedes obtener la media con summary o bien aplicando la función mean a la columna de interés.
2.6.4 Diagramas de caja (boxplots)
Los diagramas de caja son parecidos a los histogramas porque resumen la distribución de una variable continua (mediante una caja y unos segmentos que acotan las regiones donde la variable tiene el grueso de las observaciones). La representación es menos fina que la del histograma pero tiene una ventaja: permite comparar la distribución de una variable numérica en función de otra variable categórica.
boxplot(iris$Sepal.Width ~ iris$Species, col = "gray",
main = "Especies de iris\nsegún la anchura del sépalo")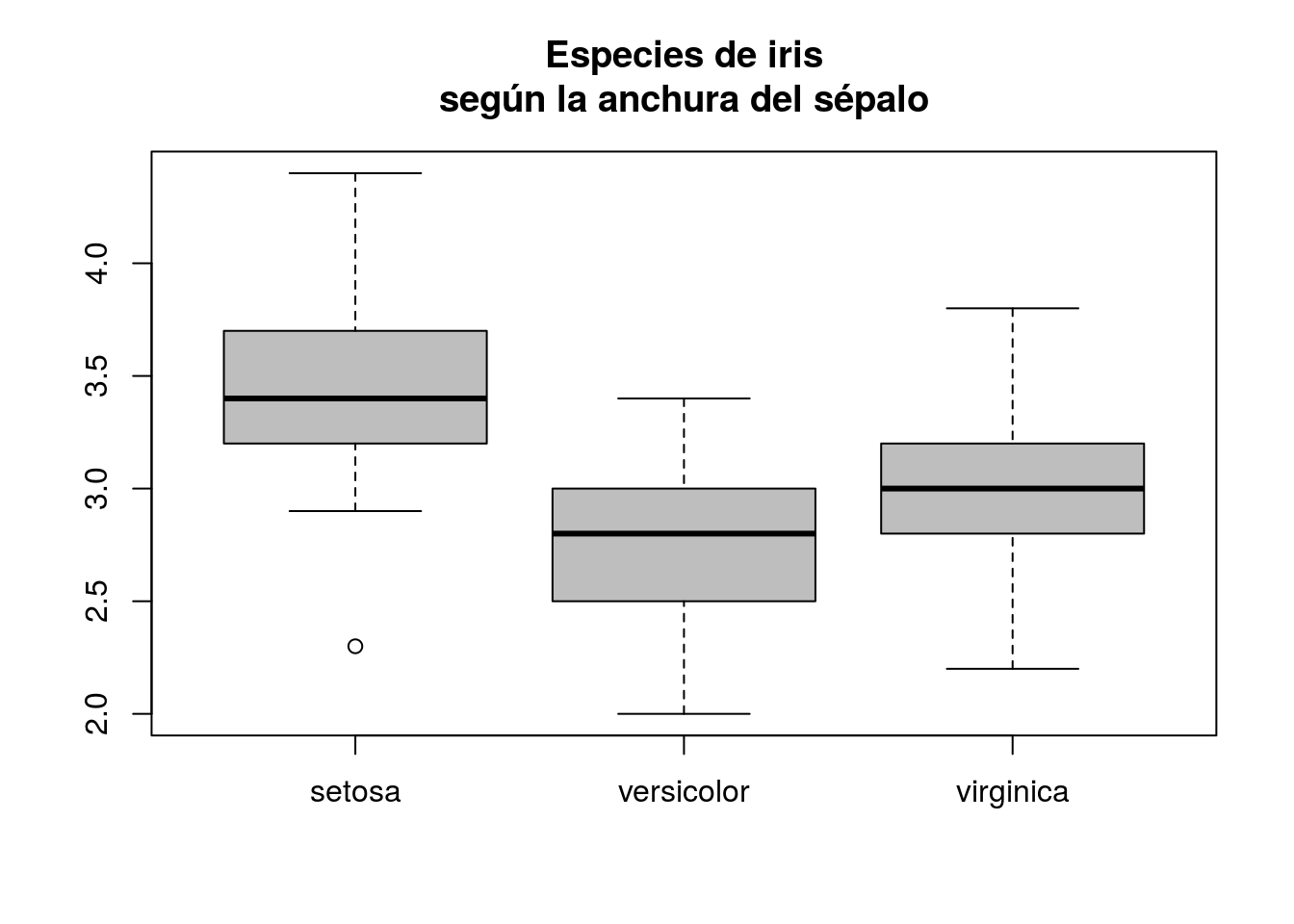
La notación y ~ x es muy común en R y significa que vas a hacer algo con y en función de x; en este caso, algo es un diagrama de cajas. Cuando construyamos modelos, también querremos entender la variable objetivo y en función de una o más variables predictoras y volveremos a hacer uso de esa notación13.
Muestra la distribución de las temperaturas en Nueva York en función del mes.
En R existe un tipo de datos muy especial:
formula; sirve para especificar relaciones entre variables y aunque fue creado para especificar modelos estadísticos, se utiliza frecuentemente en otros contextos.↩