13.3 Igualdad de medias mediante remuestreos
No es necesario utilizar pruebas estadísticas de libro para resolver el problema de la igualdad de medias (entre otros). Es más instructivo (e incluso tiene un alcance más largo) usar los ordenadores para crear pruebas ad hoc mediante remuestreos. La idea subyacente es la siguiente:
- El desempeño de dos grupos elegidos al azar nunca va a ser idéntico: tiene una variabilidad natural.
- Creando grupos al azar y midiendo la diferencia de desempeño puede medirse esa variabilidad natural.
- Cuando la diferencia entre dos grupos definidos por una determinada variable exceda esa variabilidad natural, podrá decirse que los grupos son distintos. Si no, no habría motivos para ello.
Podemos implementar esa estrategia en R. Para ello, primero, debemos calcular la diferencia entre chicos y chicas:
g3 <- mat.por$G3
sex <- mat.por$sex
medias.sexo <- tapply(g3, sex, mean)
diferencia.original <- medias.sexo["M"] - medias.sexo["F"]diferencia.original es la diferencia de medias observada en los datos. En el código que sigue vamos a asignar a los alumnos etiquetas al azar y medir las diferencias entre los grupos definidos por ellas. Lo haremos varias veces y luego veremos si la diferencia original es normal o si se sale de rango.
Para ello, primero, construiremos la función de remuestreo. Esta función aleatoriza el sexo. Eso quiere decir que asigna a los individuos una etiqueta M o F aleatoria y mide las diferencias obtenidas entre ambos grupos. Como las etiquetas se distribuyen al azar, no se esperarían diferencias de comportamiento entre los grupos. Obviamente, los promedios nunca van a ser exactamente iguales y esas diferencias (que son puro ruido estadístico) nos ayudan a determinar mediante su comparación en qué medida la diferencia entre los grupos definidos por el sexo encierran un efecto real.
remuestrea <- function(){
tmp <- tapply(g3, sample(sex), mean)
tmp["M"] - tmp["F"]
}Luego podemos llamar a esa función muchas veces para obtener otras tantas simulaciones:
diferencias.simuladas <- replicate(10000, remuestrea())En este momento disponemos de una muestra de 10000 diferencias entre grupos sin señal. De otra manera, hemos identificado el nivel de ruido del conjunto de datos, que podemos representar con un histograma. Sobre él podemos representar la diferencia real (con una línea vertical roja):
hist(diferencias.simuladas)
abline(v = diferencia.original, col = "red")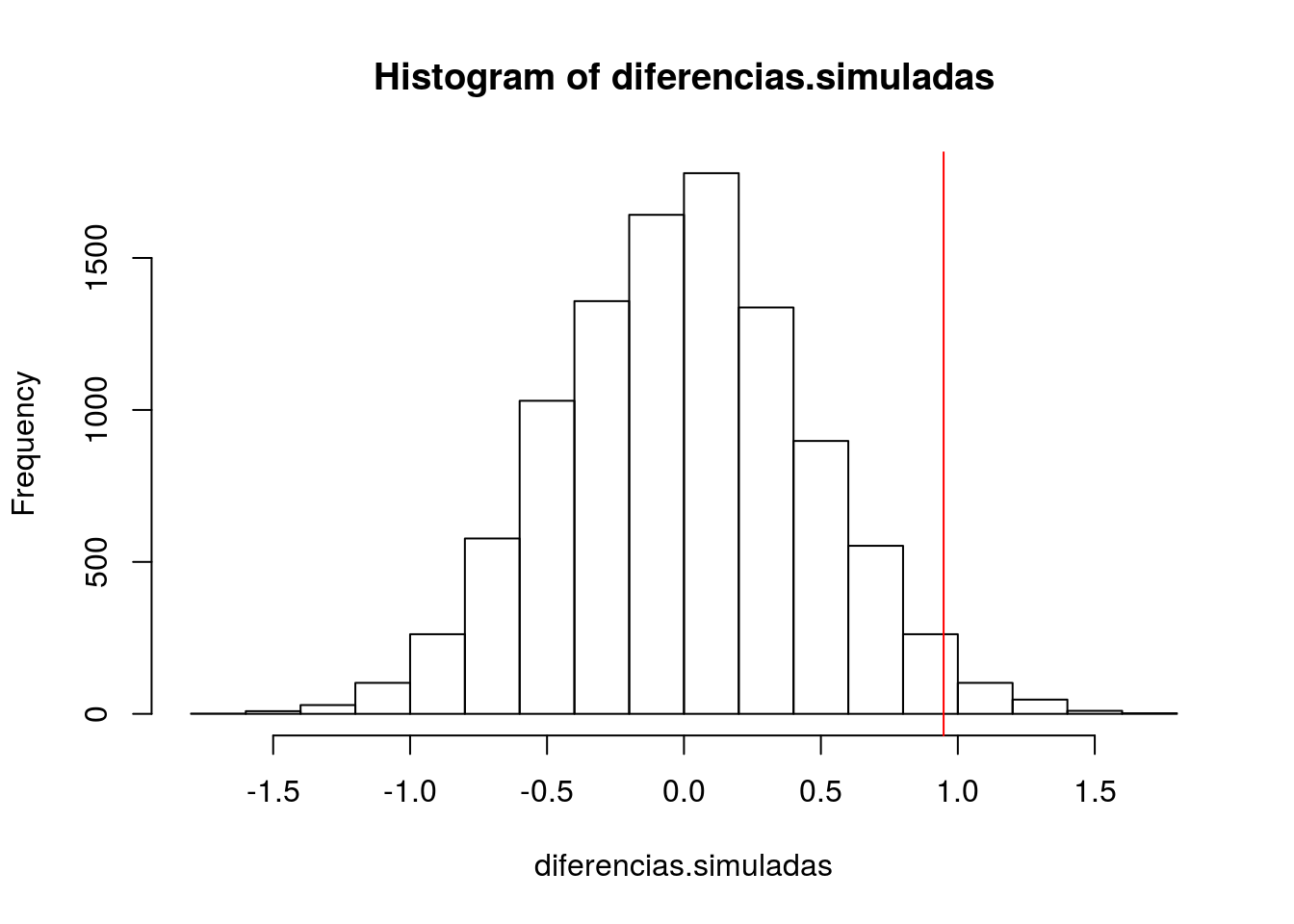
La gráfica obtenida representa la diferencia original (por sexos) dentro del universo de diferencias sin señal creadas mediante remuestreos. El p-valor (que hemos obtenido antes mediante una prueba estadística clásica) no es otra cosa que la proporción de observaciones que caen a la derecha de la línea roja. Lo podemos calcular explícitamente así:
mean(diferencias.simuladas > diferencia.original)## [1] 0.021Como se ve, aunque no exactamente igual, es similar al calculado más arriba.
En realidad, está más próxima a la mitad del p-valor calculado arriba. Esto se debe a que antes se ha calculado el p-valor correspondiente a la prueba de que la diferencia de medias sea igual a cero. En las simulaciones hemos calculado el de que esta diferenicia sea menor que cero. En un caso se trata de una de las llamadas pruebas bilaterales y en el otro, de las unilaterales. No vamos a adentrarnos en las diferencias entre ambas.